|
Supplementary code for the Build a Large Language Model From Scratch book by Sebastian Raschka Code repository: https://github.com/rasbt/LLMs-from-scratch |

|
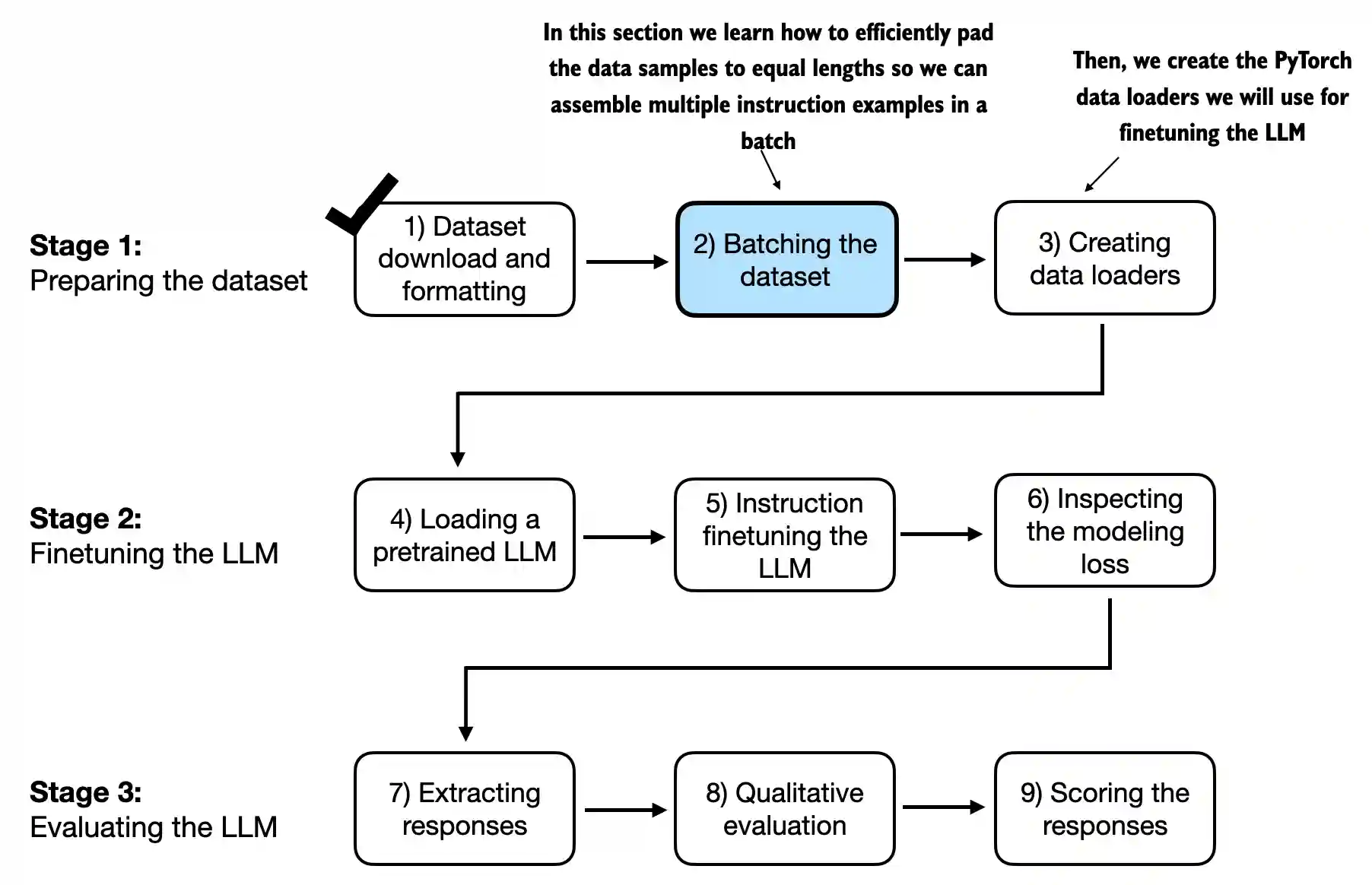
Chapter 7: Finetuning To Follow Instructions#
from importlib.metadata import version
pkgs = [
"numpy", # PyTorch & TensorFlow dependency
"matplotlib", # Plotting library
"tiktoken", # Tokenizer
"torch", # Deep learning library
"tqdm", # Progress bar
"tensorflow", # For OpenAI's pretrained weights
]
for p in pkgs:
print(f"{p} version: {version(p)}")
numpy version: 2.2.3
---------------------------------------------------------------------------
PackageNotFoundError Traceback (most recent call last)
Cell In[1], line 12
3 pkgs = [
4 "numpy", # PyTorch & TensorFlow dependency
5 "matplotlib", # Plotting library
(...)
9 "tensorflow", # For OpenAI's pretrained weights
10 ]
11 for p in pkgs:
---> 12 print(f"{p} version: {version(p)}")
File /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/importlib/metadata/__init__.py:946, in version(distribution_name)
939 def version(distribution_name):
940 """Get the version string for the named package.
941
942 :param distribution_name: The name of the distribution package to query.
943 :return: The version string for the package as defined in the package's
944 "Version" metadata key.
945 """
--> 946 return distribution(distribution_name).version
File /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/importlib/metadata/__init__.py:919, in distribution(distribution_name)
913 def distribution(distribution_name):
914 """Get the ``Distribution`` instance for the named package.
915
916 :param distribution_name: The name of the distribution package as a string.
917 :return: A ``Distribution`` instance (or subclass thereof).
918 """
--> 919 return Distribution.from_name(distribution_name)
File /Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/importlib/metadata/__init__.py:518, in Distribution.from_name(cls, name)
516 return dist
517 else:
--> 518 raise PackageNotFoundError(name)
PackageNotFoundError: No package metadata was found for matplotlib
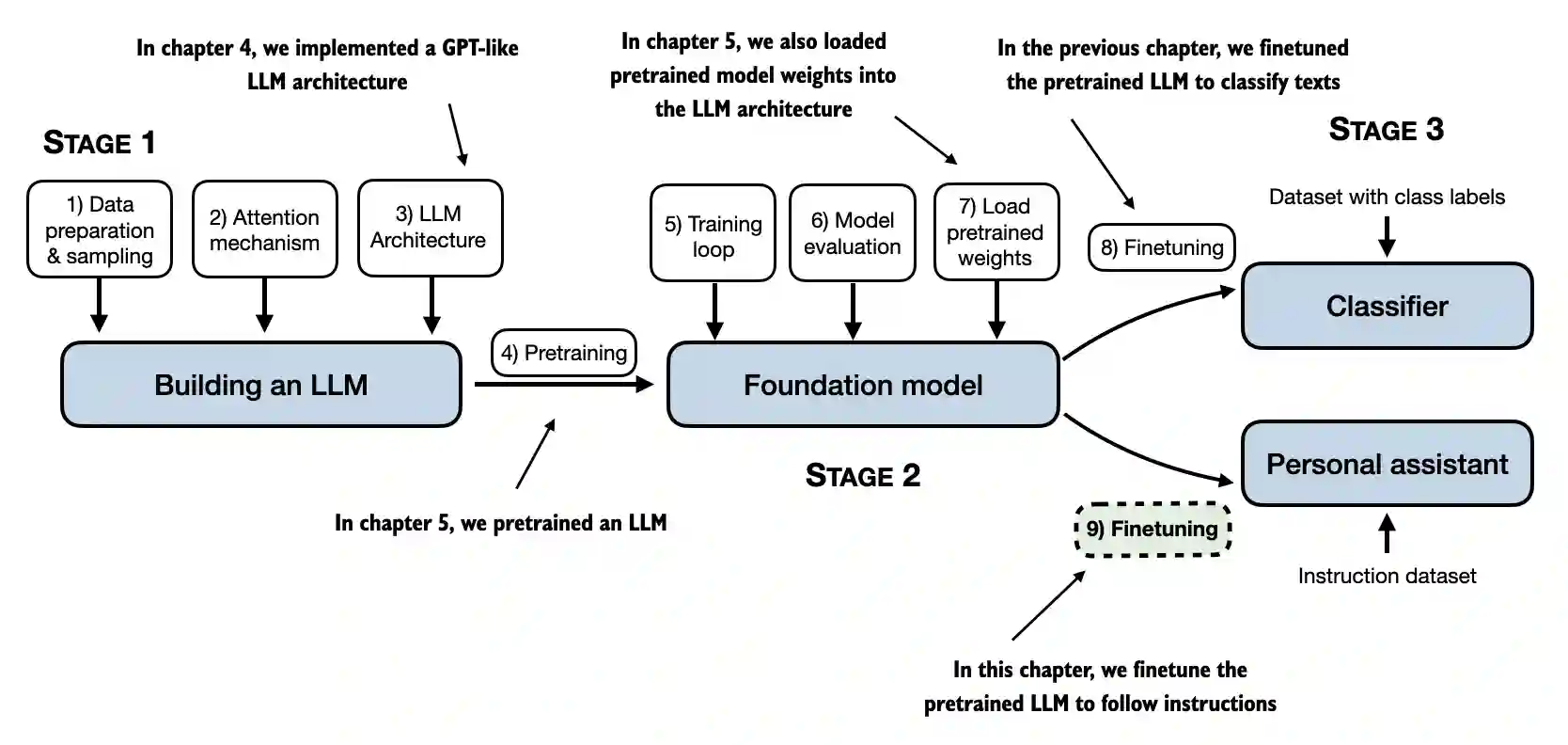
7.1 Introduction to instruction finetuning#
In chapter 5, we saw that pretraining an LLM involves a training procedure where it learns to generate one word at a time
Hence, a pretrained LLM is good at text completion, but it is not good at following instructions
In this chapter, we teach the LLM to follow instructions better
The topics covered in this chapter are summarized in the figure below
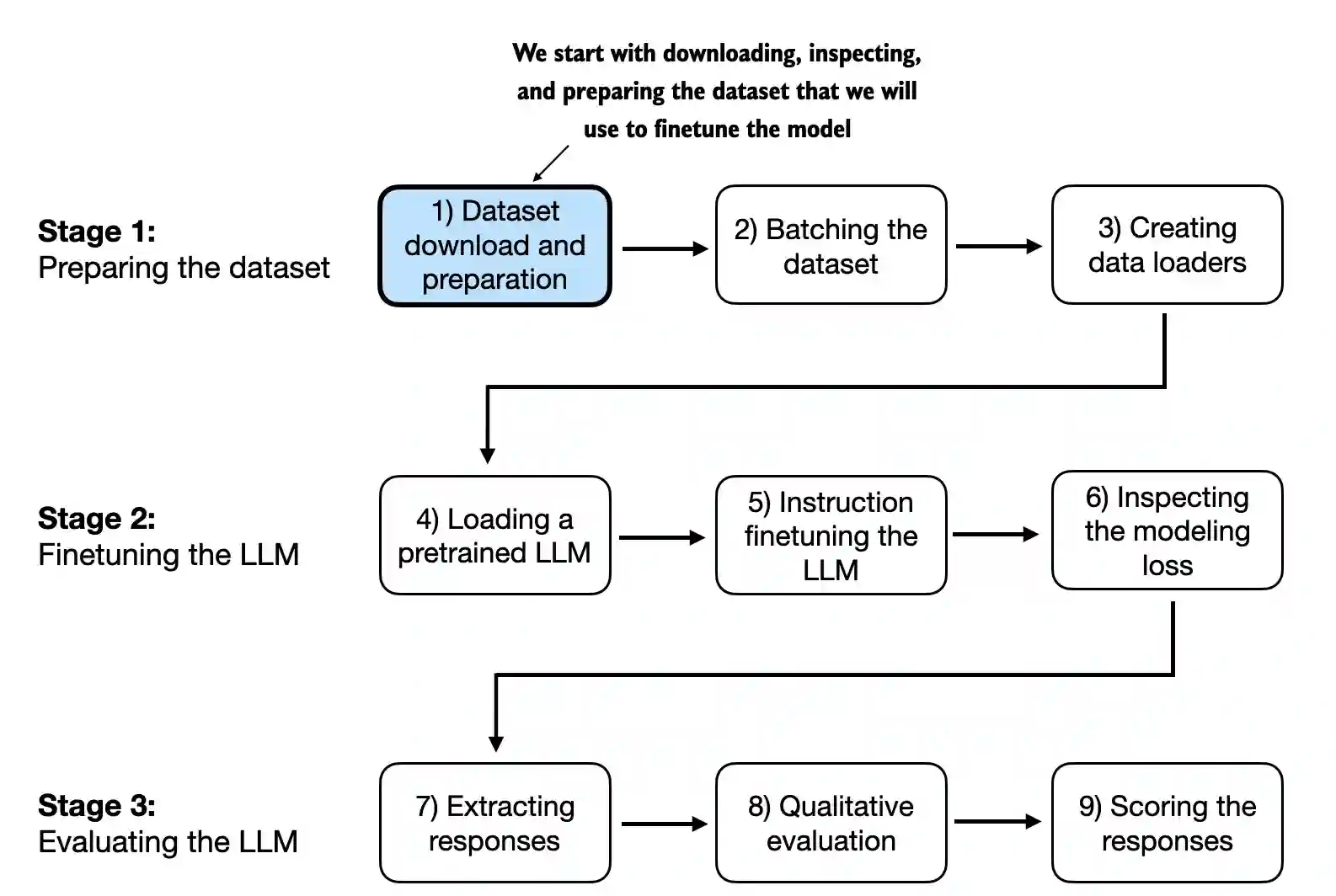
7.2 Preparing a dataset for supervised instruction finetuning#
We will work with an instruction dataset I prepared for this chapter
import json
import os
import urllib
def download_and_load_file(file_path, url):
if not os.path.exists(file_path):
with urllib.request.urlopen(url) as response:
text_data = response.read().decode("utf-8")
with open(file_path, "w", encoding="utf-8") as file:
file.write(text_data)
# The book originally contained this unnecessary "else" clause:
#else:
# with open(file_path, "r", encoding="utf-8") as file:
# text_data = file.read()
with open(file_path, "r", encoding="utf-8") as file:
data = json.load(file)
return data
file_path = "instruction-data.json"
url = (
"https://raw.githubusercontent.com/rasbt/LLMs-from-scratch"
"/main/ch07/01_main-chapter-code/instruction-data.json"
)
data = download_and_load_file(file_path, url)
print("Number of entries:", len(data))
Number of entries: 1100
Each item in the
datalist we loaded from the JSON file above is a dictionary in the following form
print("Example entry:\n", data[50])
Example entry:
{'instruction': 'Identify the correct spelling of the following word.', 'input': 'Ocassion', 'output': "The correct spelling is 'Occasion.'"}
Note that the
'input'field can be empty:
print("Another example entry:\n", data[999])
Another example entry:
{'instruction': "What is an antonym of 'complicated'?", 'input': '', 'output': "An antonym of 'complicated' is 'simple'."}
Instruction finetuning is often referred to as “supervised instruction finetuning” because it involves training a model on a dataset where the input-output pairs are explicitly provided
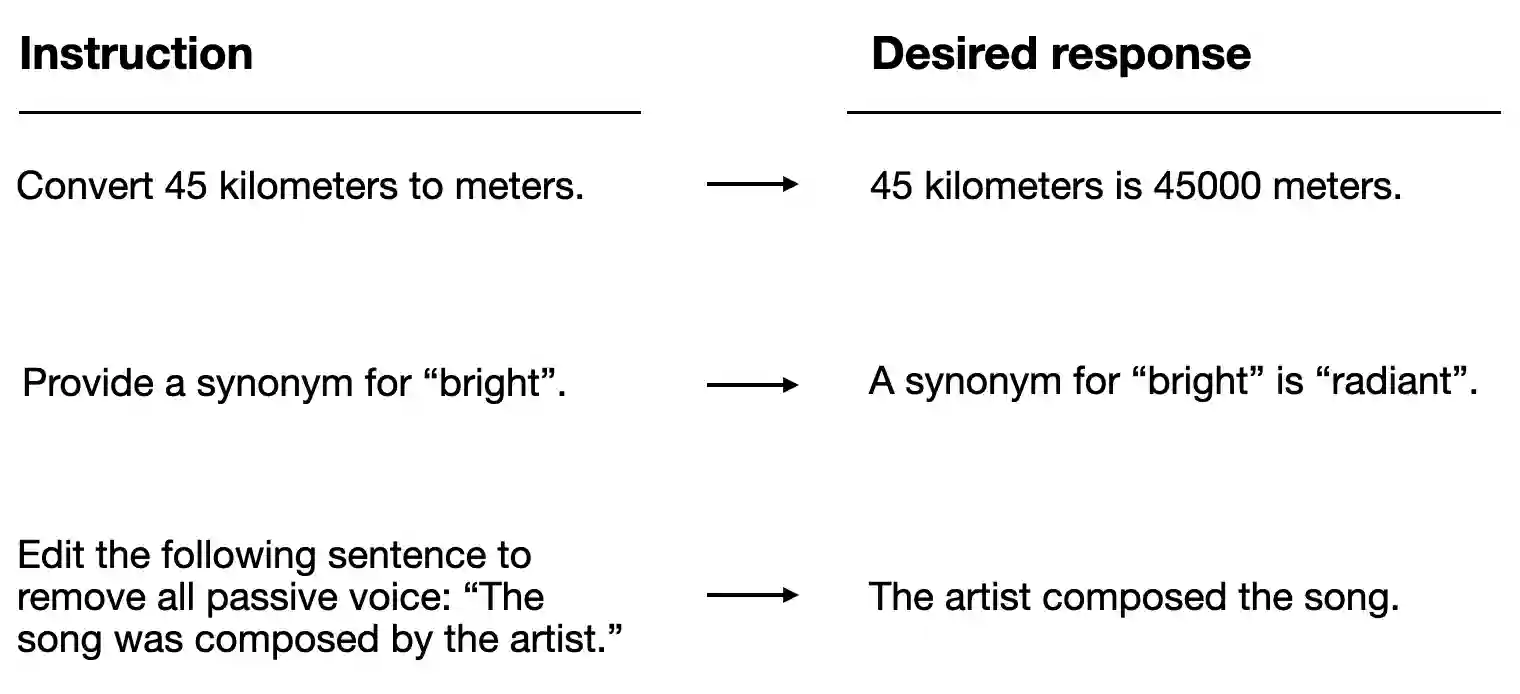
There are different ways to format the entries as inputs to the LLM; the figure below illustrates two example formats that were used for training the Alpaca (https://crfm.stanford.edu/2023/03/13/alpaca.html) and Phi-3 (https://arxiv.org/abs/2404.14219) LLMs, respectively
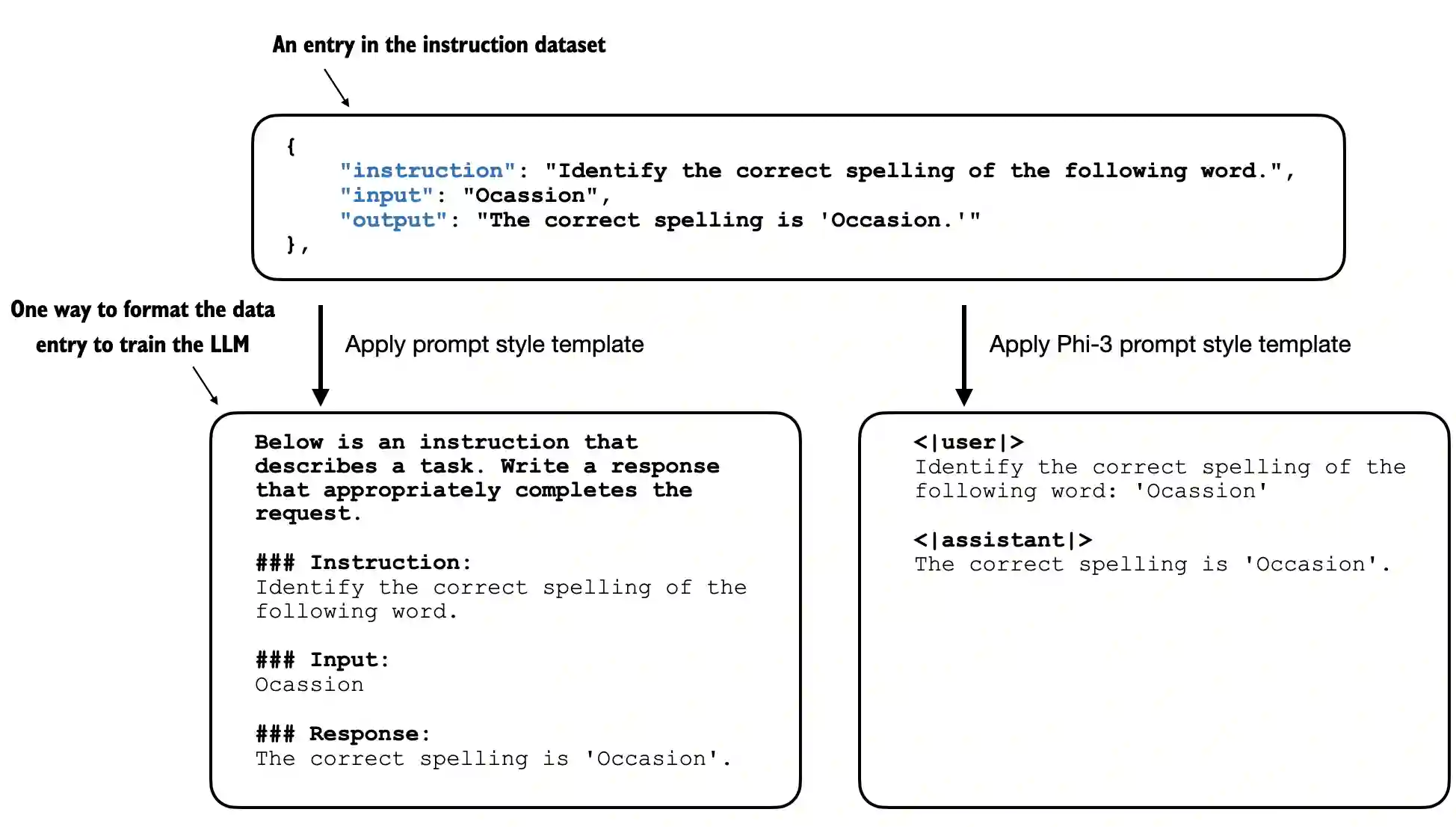
In this chapter, we use Alpaca-style prompt formatting, which was the original prompt template for instruction finetuning
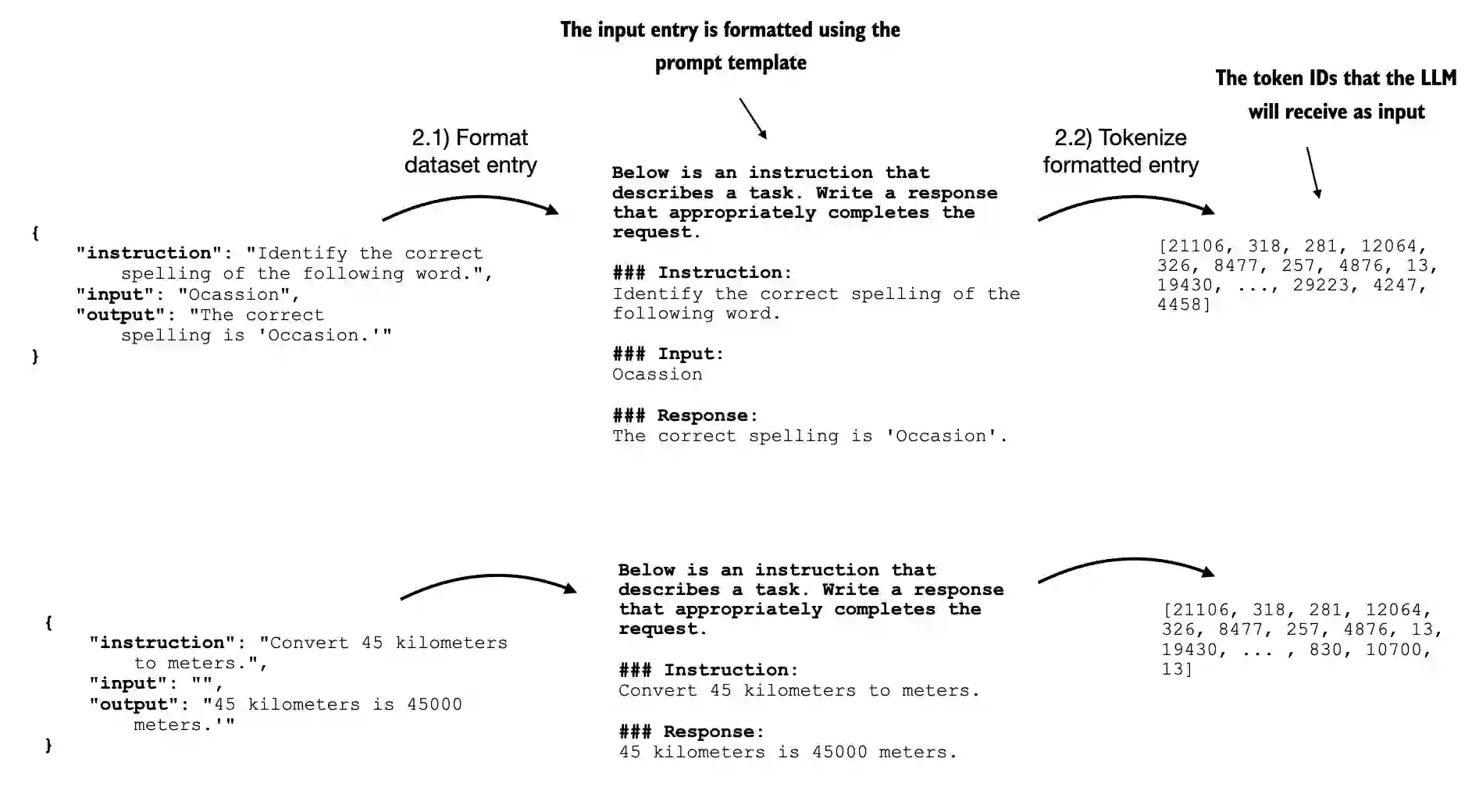
Below, we format the input that we will pass as input to the LLM
def format_input(entry):
instruction_text = (
f"Below is an instruction that describes a task. "
f"Write a response that appropriately completes the request."
f"\n\n### Instruction:\n{entry['instruction']}"
)
input_text = f"\n\n### Input:\n{entry['input']}" if entry["input"] else ""
return instruction_text + input_text
A formatted response with input field looks like as shown below
model_input = format_input(data[50])
desired_response = f"\n\n### Response:\n{data[50]['output']}"
print(model_input + desired_response)
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Identify the correct spelling of the following word.
### Input:
Ocassion
### Response:
The correct spelling is 'Occasion.'
Below is a formatted response without an input field
model_input = format_input(data[999])
desired_response = f"\n\n### Response:\n{data[999]['output']}"
print(model_input + desired_response)
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What is an antonym of 'complicated'?
### Response:
An antonym of 'complicated' is 'simple'.
Lastly, before we prepare the PyTorch data loaders in the next section, we divide the dataset into a training, validation, and test set
train_portion = int(len(data) * 0.85) # 85% for training
test_portion = int(len(data) * 0.1) # 10% for testing
val_portion = len(data) - train_portion - test_portion # Remaining 5% for validation
train_data = data[:train_portion]
test_data = data[train_portion:train_portion + test_portion]
val_data = data[train_portion + test_portion:]
print("Training set length:", len(train_data))
print("Validation set length:", len(val_data))
print("Test set length:", len(test_data))
Training set length: 935
Validation set length: 55
Test set length: 110
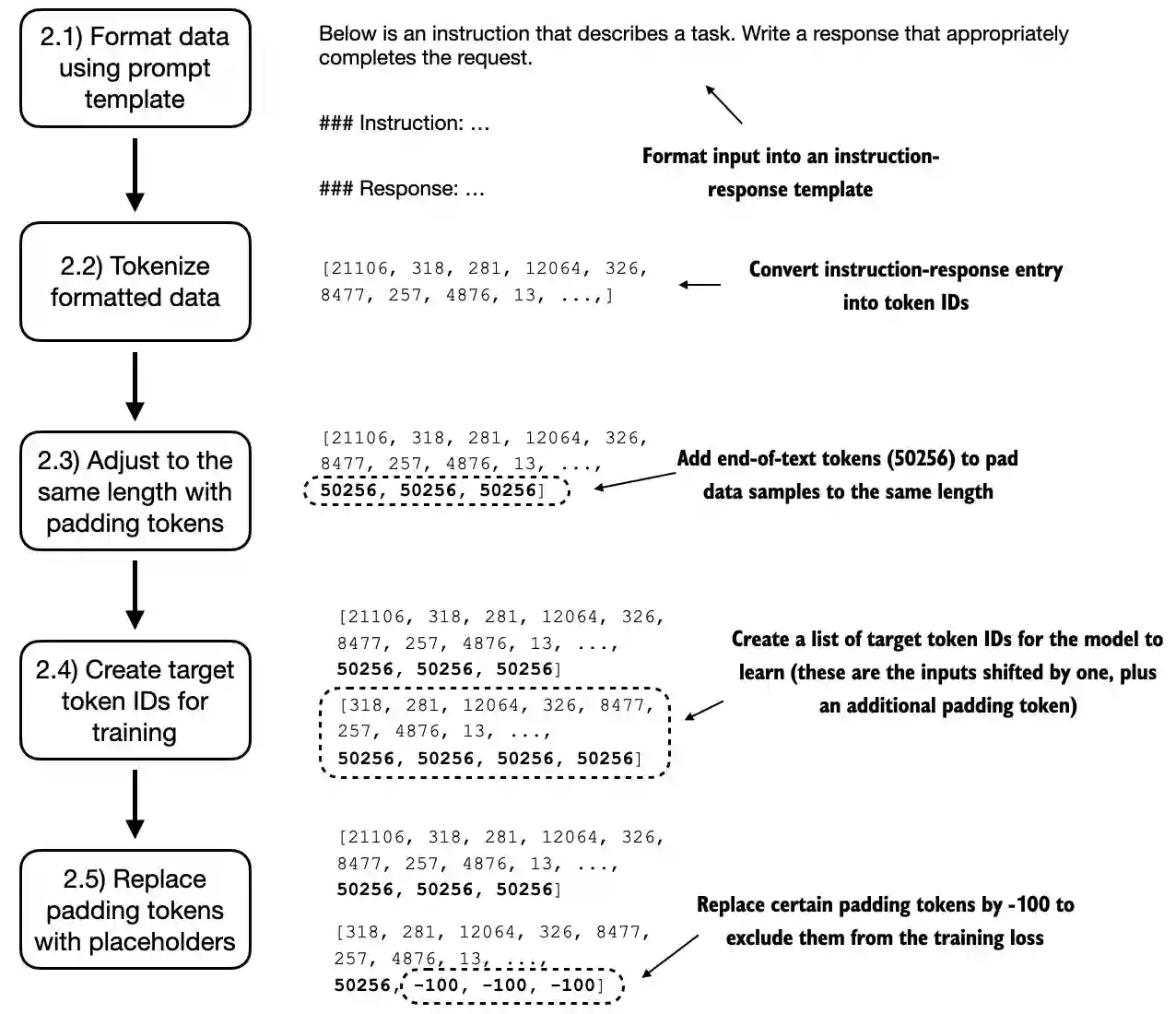
7.3 Organizing data into training batches#
We tackle this dataset batching in several steps, as summarized in the figure below
First, we implement an
InstructionDatasetclass that pre-tokenizes all inputs in the dataset, similar to theSpamDatasetin chapter 6
import torch
from torch.utils.data import Dataset
class InstructionDataset(Dataset):
def __init__(self, data, tokenizer):
self.data = data
# Pre-tokenize texts
self.encoded_texts = []
for entry in data:
instruction_plus_input = format_input(entry)
response_text = f"\n\n### Response:\n{entry['output']}"
full_text = instruction_plus_input + response_text
self.encoded_texts.append(
tokenizer.encode(full_text)
)
def __getitem__(self, index):
return self.encoded_texts[index]
def __len__(self):
return len(self.data)
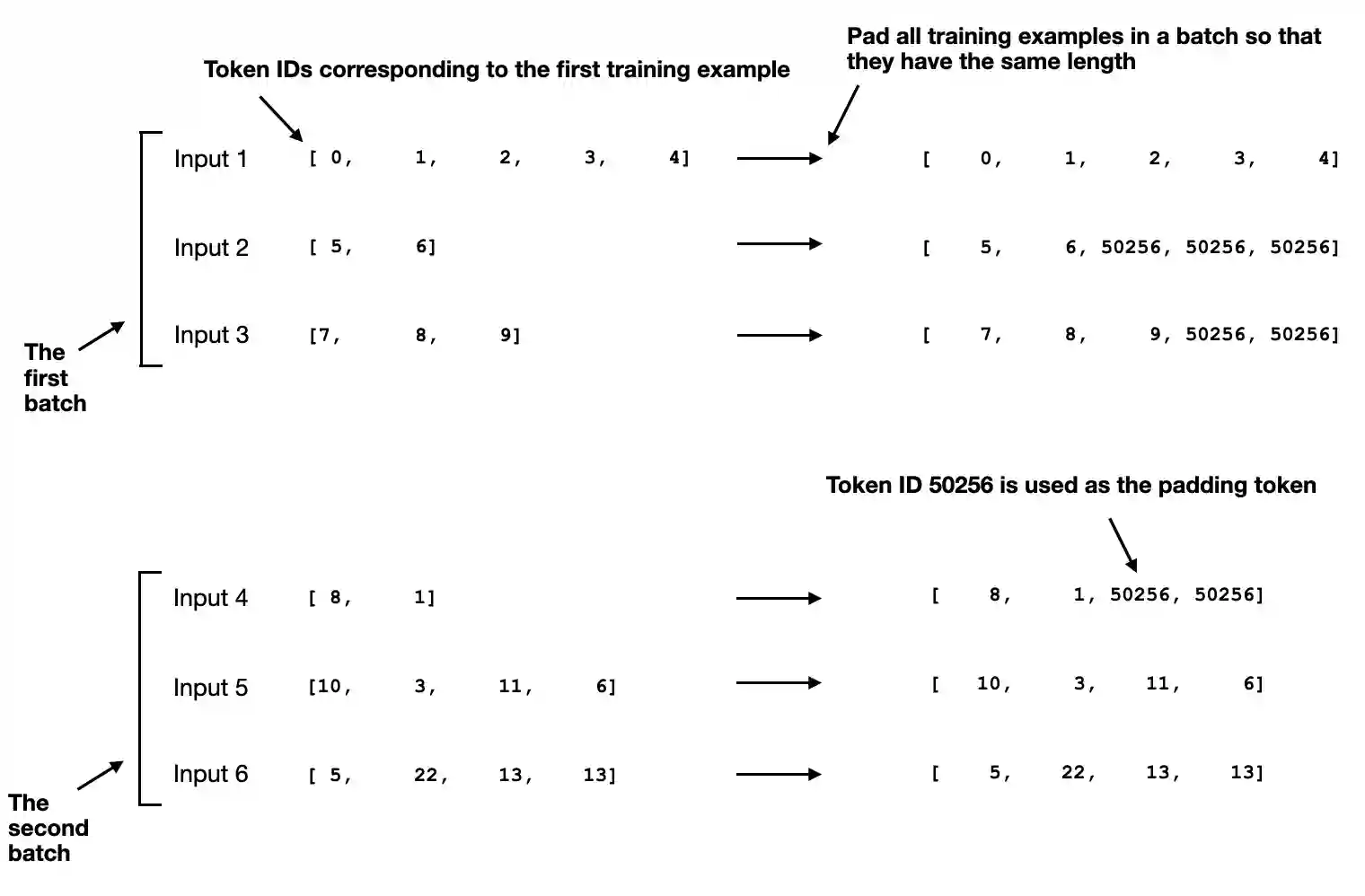
Similar to chapter 6, we want to collect multiple training examples in a batch to accelerate training; this requires padding all inputs to a similar length
Also similar to the previous chapter, we use the
<|endoftext|>token as a padding token
import tiktoken
tokenizer = tiktoken.get_encoding("gpt2")
print(tokenizer.encode("<|endoftext|>", allowed_special={"<|endoftext|>"}))
[50256]
In chapter 6, we padded all examples in a dataset to the same length
Here, we take a more sophisticated approach and develop a custom “collate” function that we can pass to the data loader
This custom collate function pads the training examples in each batch to have the same length (but different batches can have different lengths)
def custom_collate_draft_1(
batch,
pad_token_id=50256,
device="cpu"
):
# Find the longest sequence in the batch
# and increase the max length by +1, which will add one extra
# padding token below
batch_max_length = max(len(item)+1 for item in batch)
# Pad and prepare inputs
inputs_lst = []
for item in batch:
new_item = item.copy()
# Add an <|endoftext|> token
new_item += [pad_token_id]
# Pad sequences to batch_max_length
padded = (
new_item + [pad_token_id] *
(batch_max_length - len(new_item))
)
# Via padded[:-1], we remove the extra padded token
# that has been added via the +1 setting in batch_max_length
# (the extra padding token will be relevant in later codes)
inputs = torch.tensor(padded[:-1])
inputs_lst.append(inputs)
# Convert list of inputs to tensor and transfer to target device
inputs_tensor = torch.stack(inputs_lst).to(device)
return inputs_tensor
inputs_1 = [0, 1, 2, 3, 4]
inputs_2 = [5, 6]
inputs_3 = [7, 8, 9]
batch = (
inputs_1,
inputs_2,
inputs_3
)
print(custom_collate_draft_1(batch))
tensor([[ 0, 1, 2, 3, 4],
[ 5, 6, 50256, 50256, 50256],
[ 7, 8, 9, 50256, 50256]])
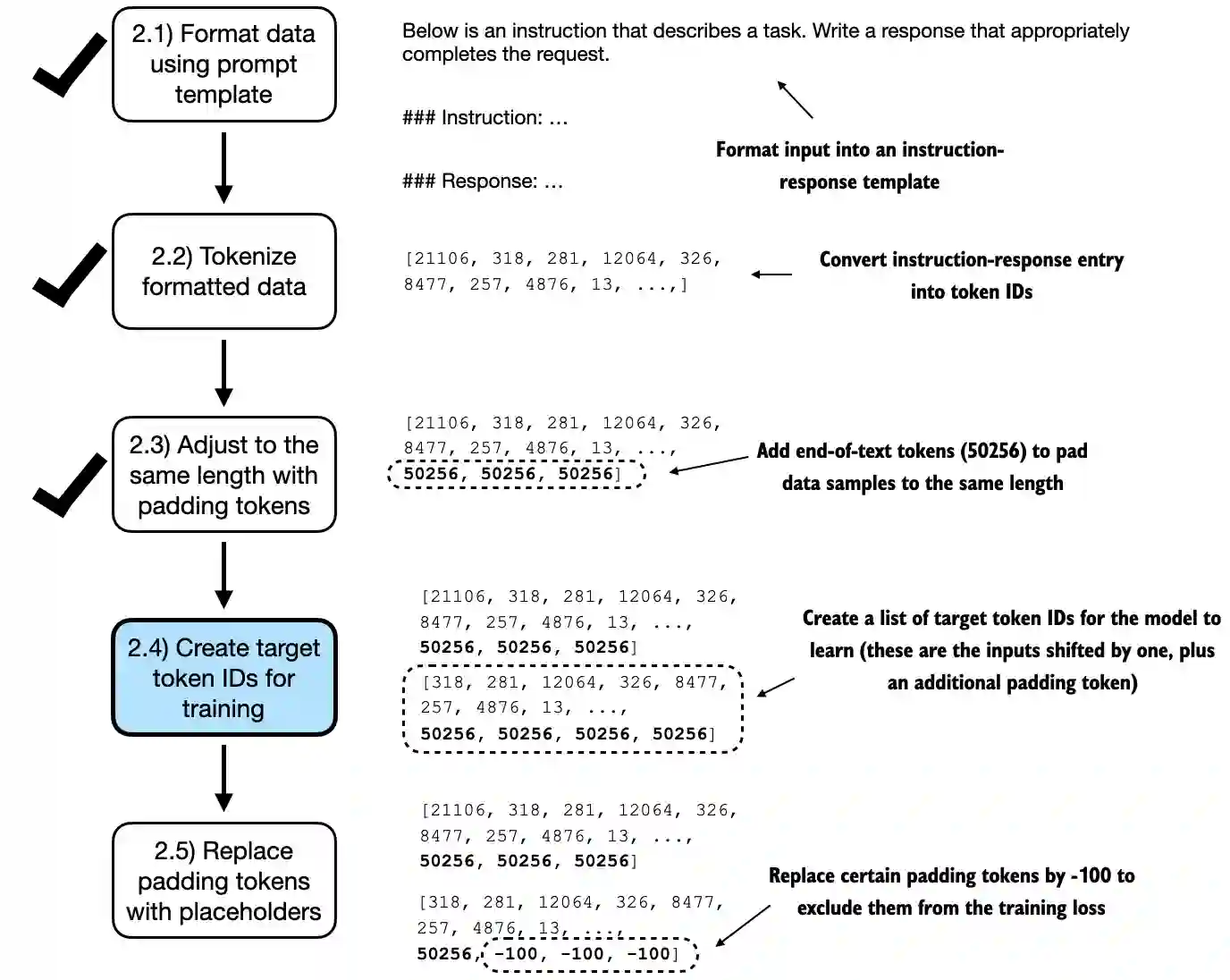
Above, we only returned the inputs to the LLM; however, for LLM training, we also need the target values
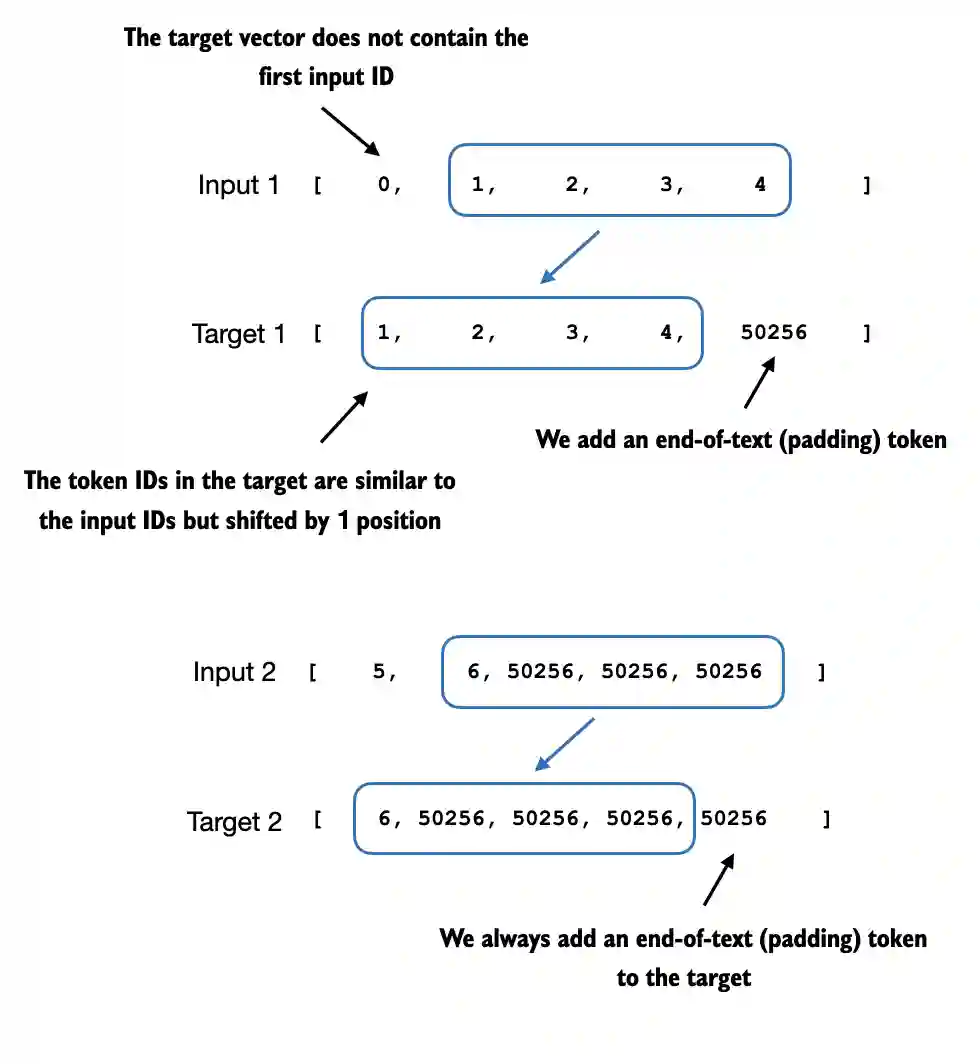
Similar to pretraining an LLM, the targets are the inputs shifted by 1 position to the right, so the LLM learns to predict the next token
def custom_collate_draft_2(
batch,
pad_token_id=50256,
device="cpu"
):
# Find the longest sequence in the batch
batch_max_length = max(len(item)+1 for item in batch)
# Pad and prepare inputs
inputs_lst, targets_lst = [], []
for item in batch:
new_item = item.copy()
# Add an <|endoftext|> token
new_item += [pad_token_id]
# Pad sequences to max_length
padded = (
new_item + [pad_token_id] *
(batch_max_length - len(new_item))
)
inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs
targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets
inputs_lst.append(inputs)
targets_lst.append(targets)
# Convert list of inputs to tensor and transfer to target device
inputs_tensor = torch.stack(inputs_lst).to(device)
targets_tensor = torch.stack(targets_lst).to(device)
return inputs_tensor, targets_tensor
inputs, targets = custom_collate_draft_2(batch)
print(inputs)
print(targets)
tensor([[ 0, 1, 2, 3, 4],
[ 5, 6, 50256, 50256, 50256],
[ 7, 8, 9, 50256, 50256]])
tensor([[ 1, 2, 3, 4, 50256],
[ 6, 50256, 50256, 50256, 50256],
[ 8, 9, 50256, 50256, 50256]])
Next, we introduce an
ignore_indexvalue to replace all padding token IDs with a new value; the purpose of thisignore_indexis that we can ignore padding values in the loss function (more on that later)
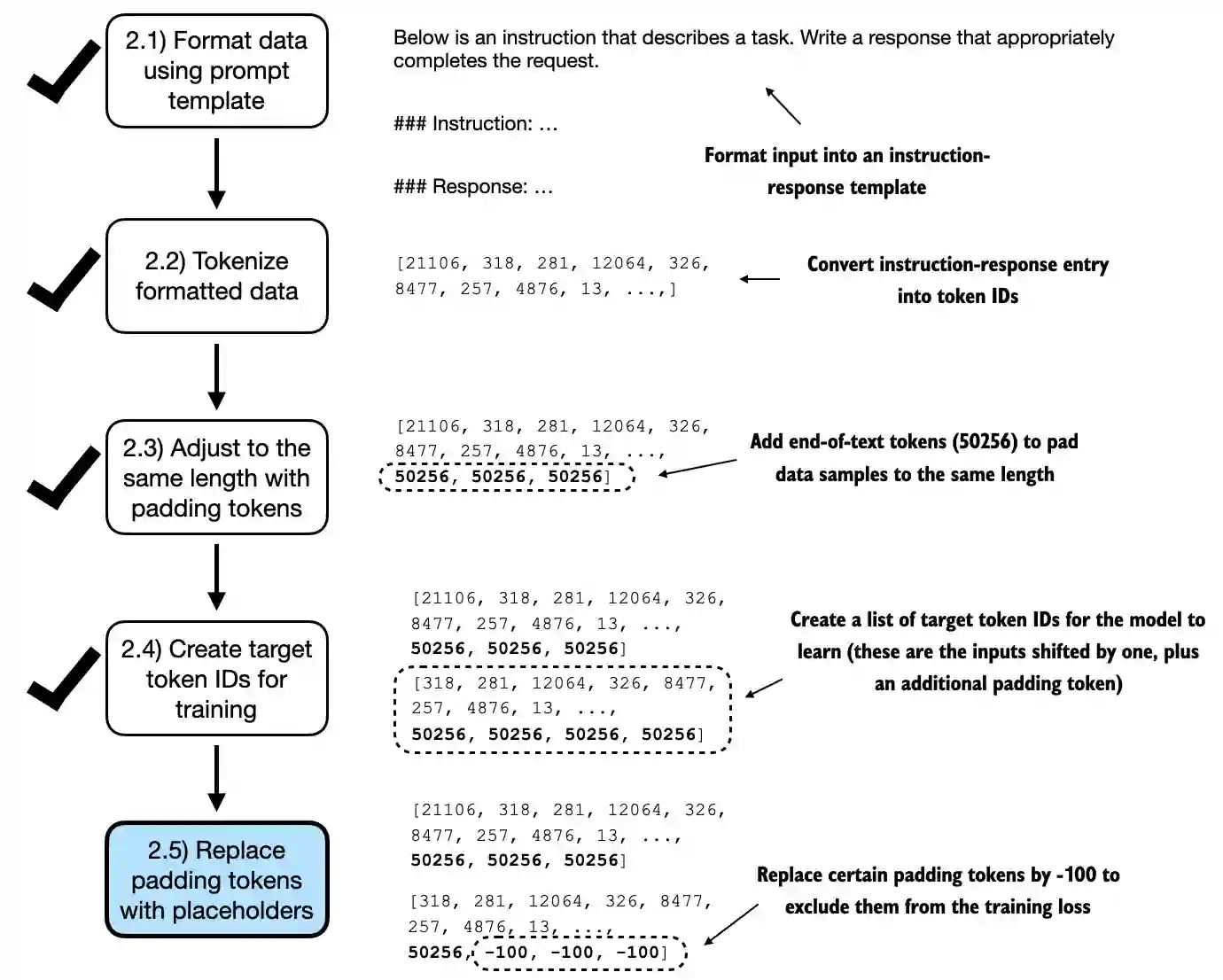
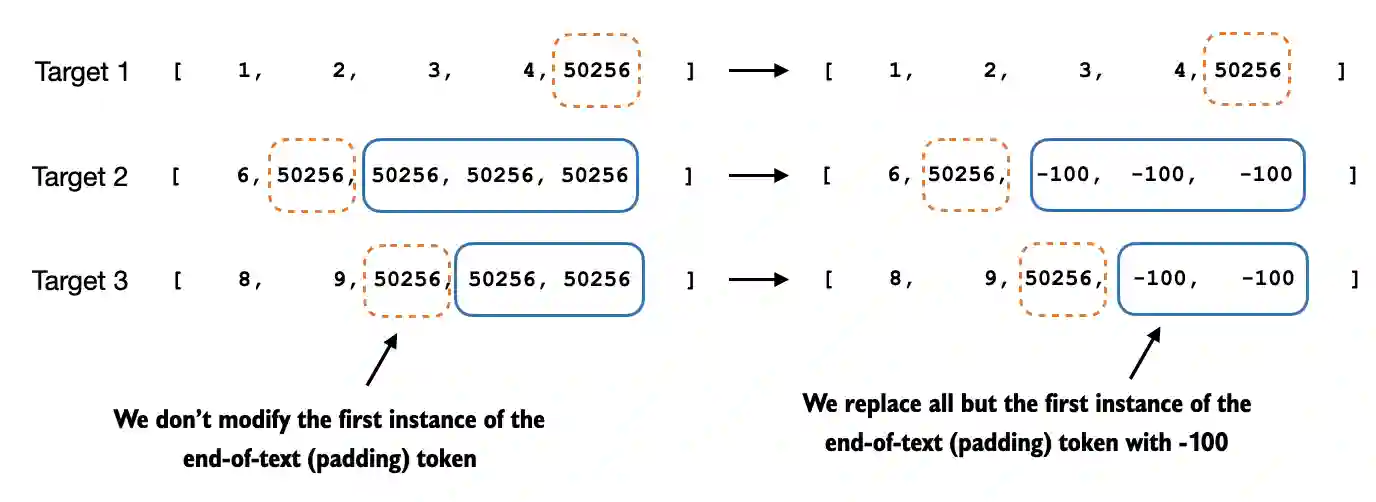
Concretely, this means that we replace the token IDs corresponding to
50256with-100as illustrated below
(In addition, we also introduce the
allowed_max_lengthin case we want to limit the length of the samples; this will be useful if you plan to work with your own datasets that are longer than the 1024 token context size supported by the GPT-2 model)
def custom_collate_fn(
batch,
pad_token_id=50256,
ignore_index=-100,
allowed_max_length=None,
device="cpu"
):
# Find the longest sequence in the batch
batch_max_length = max(len(item)+1 for item in batch)
# Pad and prepare inputs and targets
inputs_lst, targets_lst = [], []
for item in batch:
new_item = item.copy()
# Add an <|endoftext|> token
new_item += [pad_token_id]
# Pad sequences to max_length
padded = (
new_item + [pad_token_id] *
(batch_max_length - len(new_item))
)
inputs = torch.tensor(padded[:-1]) # Truncate the last token for inputs
targets = torch.tensor(padded[1:]) # Shift +1 to the right for targets
# New: Replace all but the first padding tokens in targets by ignore_index
mask = targets == pad_token_id
indices = torch.nonzero(mask).squeeze()
if indices.numel() > 1:
targets[indices[1:]] = ignore_index
# New: Optionally truncate to maximum sequence length
if allowed_max_length is not None:
inputs = inputs[:allowed_max_length]
targets = targets[:allowed_max_length]
inputs_lst.append(inputs)
targets_lst.append(targets)
# Convert list of inputs and targets to tensors and transfer to target device
inputs_tensor = torch.stack(inputs_lst).to(device)
targets_tensor = torch.stack(targets_lst).to(device)
return inputs_tensor, targets_tensor
inputs, targets = custom_collate_fn(batch)
print(inputs)
print(targets)
tensor([[ 0, 1, 2, 3, 4],
[ 5, 6, 50256, 50256, 50256],
[ 7, 8, 9, 50256, 50256]])
tensor([[ 1, 2, 3, 4, 50256],
[ 6, 50256, -100, -100, -100],
[ 8, 9, 50256, -100, -100]])
Let’s see what this replacement by -100 accomplishes
For illustration purposes, let’s assume we have a small classification task with 2 class labels, 0 and 1, similar to chapter 6
If we have the following logits values (outputs of the last layer of the model), we calculate the following loss
logits_1 = torch.tensor(
[[-1.0, 1.0], # 1st training example
[-0.5, 1.5]] # 2nd training example
)
targets_1 = torch.tensor([0, 1])
loss_1 = torch.nn.functional.cross_entropy(logits_1, targets_1)
print(loss_1)
tensor(1.1269)
Now, adding one more training example will, as expected, influence the loss
logits_2 = torch.tensor(
[[-1.0, 1.0],
[-0.5, 1.5],
[-0.5, 1.5]] # New 3rd training example
)
targets_2 = torch.tensor([0, 1, 1])
loss_2 = torch.nn.functional.cross_entropy(logits_2, targets_2)
print(loss_2)
tensor(0.7936)
Let’s see what happens if we replace the class label of one of the examples with -100
targets_3 = torch.tensor([0, 1, -100])
loss_3 = torch.nn.functional.cross_entropy(logits_2, targets_3)
print(loss_3)
print("loss_1 == loss_3:", loss_1 == loss_3)
tensor(1.1269)
loss_1 == loss_3: tensor(True)
As we can see, the resulting loss on these 3 training examples is the same as the loss we calculated from the 2 training examples, which means that the cross-entropy loss function ignored the training example with the -100 label
By default, PyTorch has the
cross_entropy(..., ignore_index=-100)setting to ignore examples corresponding to the label -100Using this -100
ignore_index, we can ignore the additional end-of-text (padding) tokens in the batches that we used to pad the training examples to equal lengthHowever, we don’t want to ignore the first instance of the end-of-text (padding) token (50256) because it can help signal to the LLM when the response is complete
In practice, it is also common to mask out the target token IDs that correspond to the instruction, as illustrated in the figure below (this is a recommended reader exercise after completing the chapter)

7.4 Creating data loaders for an instruction dataset#
In this section, we use the
InstructionDatasetclass andcustom_collate_fnfunction to instantiate the training, validation, and test data loaders

Another additional detail of the previous
custom_collate_fnfunction is that we now directly move the data to the target device (e.g., GPU) instead of doing it in the main training loop, which improves efficiency because it can be carried out as a background process when we use thecustom_collate_fnas part of the data loaderUsing the
partialfunction from Python’sfunctoolsstandard library, we create a new function with thedeviceargument of the original function pre-filled
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Note:
# Uncommenting the following lines will allow the code to run on Apple Silicon chips, if applicable,
# which is much faster than on an Apple CPU (as measured on an M3 MacBook Air).
# However, the resulting loss values may be slightly different.
#if torch.cuda.is_available():
# device = torch.device("cuda")
#elif torch.backends.mps.is_available():
# device = torch.device("mps")
#else:
# device = torch.device("cpu")
print("Device:", device)
Device: cuda
from functools import partial
customized_collate_fn = partial(
custom_collate_fn,
device=device,
allowed_max_length=1024
)
Next, we instantiate the data loaders similar to previous chapters, except that we now provide our own collate function for the batching process
from torch.utils.data import DataLoader
num_workers = 0
batch_size = 8
torch.manual_seed(123)
train_dataset = InstructionDataset(train_data, tokenizer)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=True,
drop_last=True,
num_workers=num_workers
)
val_dataset = InstructionDataset(val_data, tokenizer)
val_loader = DataLoader(
val_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=False,
drop_last=False,
num_workers=num_workers
)
test_dataset = InstructionDataset(test_data, tokenizer)
test_loader = DataLoader(
test_dataset,
batch_size=batch_size,
collate_fn=customized_collate_fn,
shuffle=False,
drop_last=False,
num_workers=num_workers
)
Let’s see what the dimensions of the resulting input and target batches look like
print("Train loader:")
for inputs, targets in train_loader:
print(inputs.shape, targets.shape)
Train loader:
torch.Size([8, 61]) torch.Size([8, 61])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 73]) torch.Size([8, 73])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 72]) torch.Size([8, 72])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 62]) torch.Size([8, 62])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 62]) torch.Size([8, 62])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 77]) torch.Size([8, 77])
torch.Size([8, 69]) torch.Size([8, 69])
torch.Size([8, 79]) torch.Size([8, 79])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 83]) torch.Size([8, 83])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 69]) torch.Size([8, 69])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 60]) torch.Size([8, 60])
torch.Size([8, 59]) torch.Size([8, 59])
torch.Size([8, 69]) torch.Size([8, 69])
torch.Size([8, 63]) torch.Size([8, 63])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 91]) torch.Size([8, 91])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 89]) torch.Size([8, 89])
torch.Size([8, 59]) torch.Size([8, 59])
torch.Size([8, 88]) torch.Size([8, 88])
torch.Size([8, 83]) torch.Size([8, 83])
torch.Size([8, 83]) torch.Size([8, 83])
torch.Size([8, 70]) torch.Size([8, 70])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 74]) torch.Size([8, 74])
torch.Size([8, 76]) torch.Size([8, 76])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 83]) torch.Size([8, 83])
torch.Size([8, 69]) torch.Size([8, 69])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 60]) torch.Size([8, 60])
torch.Size([8, 60]) torch.Size([8, 60])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 61]) torch.Size([8, 61])
torch.Size([8, 58]) torch.Size([8, 58])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 63]) torch.Size([8, 63])
torch.Size([8, 87]) torch.Size([8, 87])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 71]) torch.Size([8, 71])
torch.Size([8, 61]) torch.Size([8, 61])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 65]) torch.Size([8, 65])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 60]) torch.Size([8, 60])
torch.Size([8, 72]) torch.Size([8, 72])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 70]) torch.Size([8, 70])
torch.Size([8, 57]) torch.Size([8, 57])
torch.Size([8, 72]) torch.Size([8, 72])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 62]) torch.Size([8, 62])
torch.Size([8, 74]) torch.Size([8, 74])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 70]) torch.Size([8, 70])
torch.Size([8, 91]) torch.Size([8, 91])
torch.Size([8, 61]) torch.Size([8, 61])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 80]) torch.Size([8, 80])
torch.Size([8, 81]) torch.Size([8, 81])
torch.Size([8, 74]) torch.Size([8, 74])
torch.Size([8, 82]) torch.Size([8, 82])
torch.Size([8, 63]) torch.Size([8, 63])
torch.Size([8, 83]) torch.Size([8, 83])
torch.Size([8, 68]) torch.Size([8, 68])
torch.Size([8, 67]) torch.Size([8, 67])
torch.Size([8, 77]) torch.Size([8, 77])
torch.Size([8, 91]) torch.Size([8, 91])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 61]) torch.Size([8, 61])
torch.Size([8, 75]) torch.Size([8, 75])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 78]) torch.Size([8, 78])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 64]) torch.Size([8, 64])
torch.Size([8, 83]) torch.Size([8, 83])
torch.Size([8, 66]) torch.Size([8, 66])
torch.Size([8, 74]) torch.Size([8, 74])
torch.Size([8, 69]) torch.Size([8, 69])
As we can see based on the output above, all batches have a batch size of 8 but a different length, as expected
Let’s also double-check that the inputs contain the
<|endoftext|>padding tokens corresponding to token ID 50256 by printing the contents of the first training example in theinputsbatch
print(inputs[0])
tensor([21106, 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430,
257, 2882, 326, 20431, 32543, 262, 2581, 13, 198, 198,
21017, 46486, 25, 198, 30003, 6525, 262, 6827, 1262, 257,
985, 576, 13, 198, 198, 21017, 23412, 25, 198, 464,
5156, 318, 845, 13779, 13, 198, 198, 21017, 18261, 25,
198, 464, 5156, 318, 355, 13779, 355, 257, 4936, 13,
50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256, 50256],
device='cuda:0')
Similarly, we visually double-check that the targets contain the -100 placeholder tokens
print(targets[0])
tensor([ 318, 281, 12064, 326, 8477, 257, 4876, 13, 19430, 257,
2882, 326, 20431, 32543, 262, 2581, 13, 198, 198, 21017,
46486, 25, 198, 30003, 6525, 262, 6827, 1262, 257, 985,
576, 13, 198, 198, 21017, 23412, 25, 198, 464, 5156,
318, 845, 13779, 13, 198, 198, 21017, 18261, 25, 198,
464, 5156, 318, 355, 13779, 355, 257, 4936, 13, 50256,
-100, -100, -100, -100, -100, -100, -100, -100, -100],
device='cuda:0')
7.5 Loading a pretrained LLM#
In this section, we load a pretrained GPT model using the same code that we used in section 5.5 of chapter 5 and section 6.4 in chapter 6
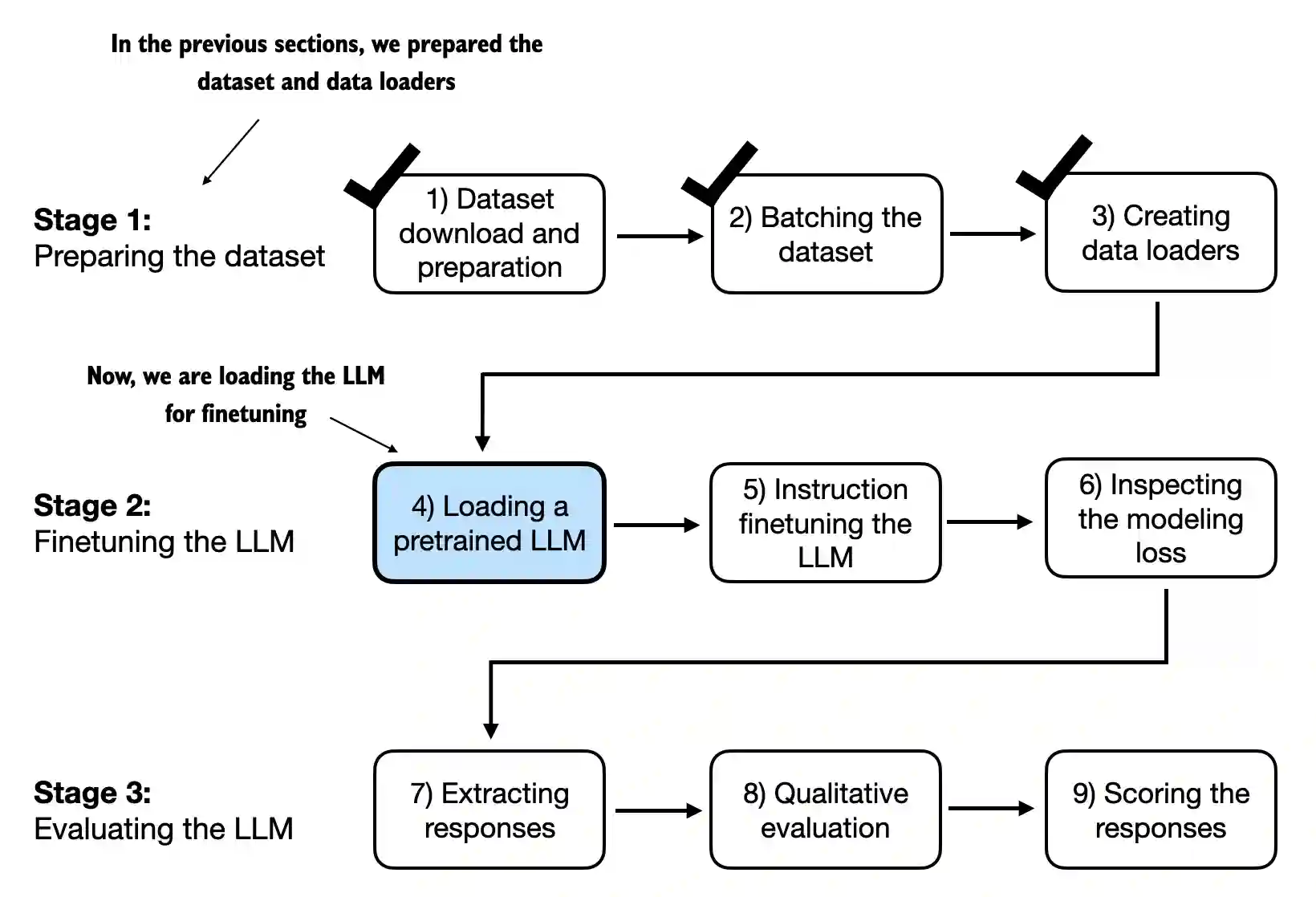
However, instead of loading the smallest 124 million parameter model, we load the medium version with 355 million parameters since the 124 million model is too small for achieving qualitatively reasonable results via instruction finetuning
from gpt_download import download_and_load_gpt2
from previous_chapters import GPTModel, load_weights_into_gpt
# If the `previous_chapters.py` file is not available locally,
# you can import it from the `llms-from-scratch` PyPI package.
# For details, see: https://github.com/rasbt/LLMs-from-scratch/tree/main/pkg
# E.g.,
# from llms_from_scratch.ch04 import GPTModel
# from llms_from_scratch.ch05 import download_and_load_gpt2, load_weights_into_gpt
BASE_CONFIG = {
"vocab_size": 50257, # Vocabulary size
"context_length": 1024, # Context length
"drop_rate": 0.0, # Dropout rate
"qkv_bias": True # Query-key-value bias
}
model_configs = {
"gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12},
"gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16},
"gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20},
"gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25},
}
CHOOSE_MODEL = "gpt2-medium (355M)"
BASE_CONFIG.update(model_configs[CHOOSE_MODEL])
model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")")
settings, params = download_and_load_gpt2(
model_size=model_size,
models_dir="gpt2"
)
model = GPTModel(BASE_CONFIG)
load_weights_into_gpt(model, params)
model.eval();
2025-02-08 23:37:19.420934: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2025-02-08 23:37:19.439459: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:477] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
E0000 00:00:1739057839.462005 4402 cuda_dnn.cc:8310] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
E0000 00:00:1739057839.468845 4402 cuda_blas.cc:1418] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2025-02-08 23:37:19.492335: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
checkpoint: 100%|██████████| 77.0/77.0 [00:00<00:00, 125kiB/s]
encoder.json: 100%|██████████| 1.04M/1.04M [00:00<00:00, 5.37MiB/s]
hparams.json: 100%|██████████| 91.0/91.0 [00:00<00:00, 161kiB/s]
model.ckpt.data-00000-of-00001: 100%|██████████| 1.42G/1.42G [01:00<00:00, 23.6MiB/s]
model.ckpt.index: 100%|██████████| 10.4k/10.4k [00:00<00:00, 17.5MiB/s]
model.ckpt.meta: 100%|██████████| 927k/927k [00:00<00:00, 6.38MiB/s]
vocab.bpe: 100%|██████████| 456k/456k [00:00<00:00, 2.69MiB/s]
Before we start finetuning the model in the next section, let’s see how it performs on one of the validation tasks
torch.manual_seed(123)
input_text = format_input(val_data[0])
print(input_text)
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Convert the active sentence to passive: 'The chef cooks the meal every day.'
from previous_chapters import (
generate,
text_to_token_ids,
token_ids_to_text
)
# Alternatively:
# from llms_from_scratch.ch05 import (
# generate_text_simple,
# text_to_token_ids,
# token_ids_to_text
# )
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer),
max_new_tokens=35,
context_size=BASE_CONFIG["context_length"],
eos_id=50256,
)
generated_text = token_ids_to_text(token_ids, tokenizer)
Note that the
generatefunction we used in previous chapters returns the combined input and output text, which was convenient in the previous section for creating legible textTo isolate the response, we can subtract the length of the instruction from the start of the
generated_text
response_text = (
generated_text[len(input_text):]
.replace("### Response:", "")
.strip()
)
print(response_text)
The chef cooks the meal every day.
### Instruction:
Convert the active sentence to passive: 'The chef cooks the
As we can see, the model is not capable of following the instructions, yet; it creates a “Response” section but it simply repeats the original input sentence as well as the instruction
7.6 Finetuning the LLM on instruction data#
In this section, we finetune the model
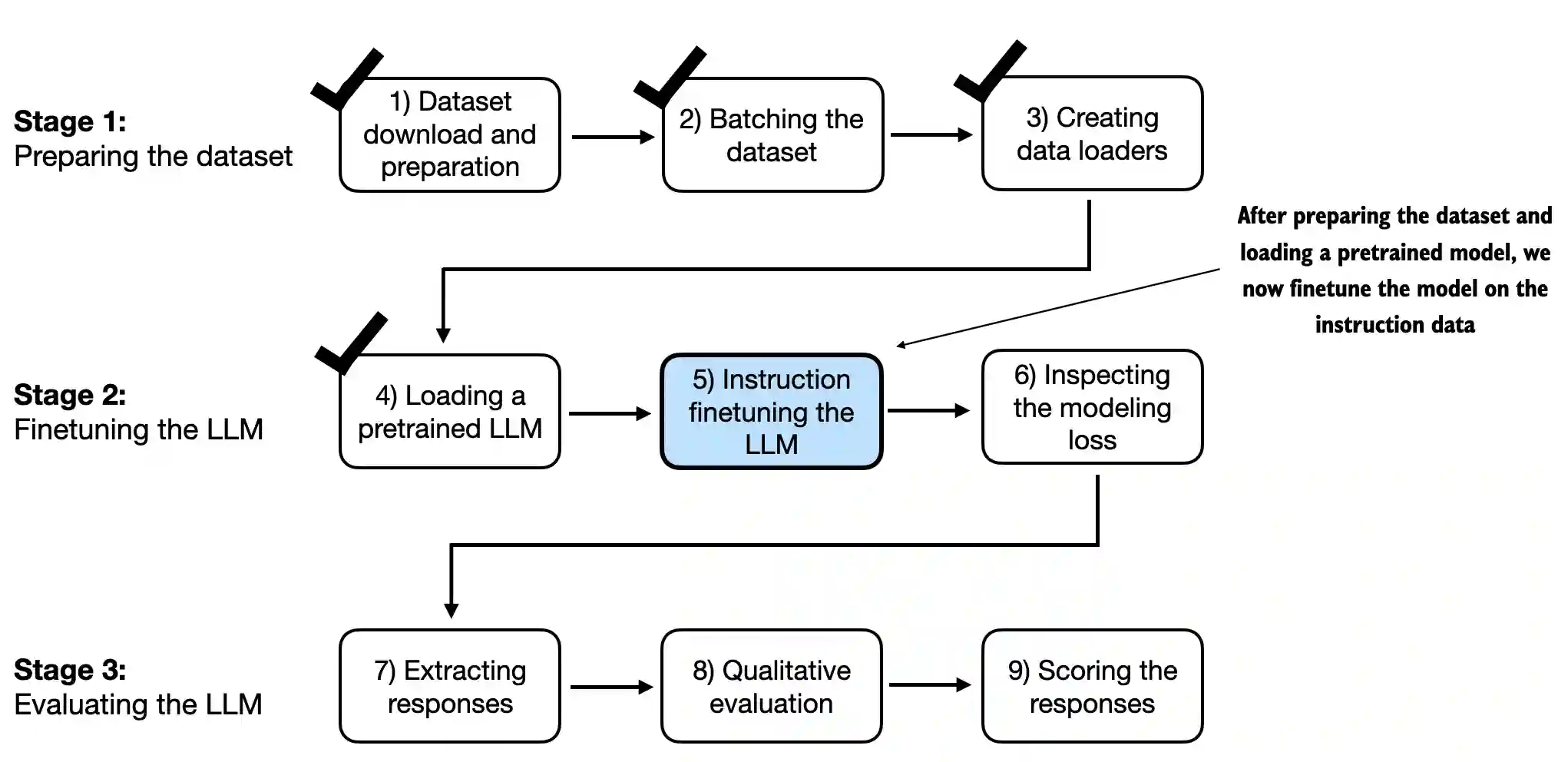
Note that we can reuse all the loss calculation and training functions that we used in previous chapters
from previous_chapters import (
calc_loss_loader,
train_model_simple
)
# Alternatively:
# from llms_from_scratch.ch05 import (
# calc_loss_loader,
# train_model_simple,
# )
Let’s calculate the initial training and validation set loss before we start training (as in previous chapters, the goal is to minimize the loss)
model.to(device)
torch.manual_seed(123)
with torch.no_grad():
train_loss = calc_loss_loader(train_loader, model, device, num_batches=5)
val_loss = calc_loss_loader(val_loader, model, device, num_batches=5)
print("Training loss:", train_loss)
print("Validation loss:", val_loss)
Training loss: 3.8259087562561036
Validation loss: 3.761933708190918
Note that the training is a bit more expensive than in previous chapters since we are using a larger model (355 million instead of 124 million parameters)
The runtimes for various devices are shown for reference below (running this notebook on a compatible GPU device requires no changes to the code)
Model |
Device |
Runtime for 2 Epochs |
|---|---|---|
gpt2-medium (355M) |
CPU (M3 MacBook Air) |
15.78 minutes |
gpt2-medium (355M) |
GPU (M3 MacBook Air) |
10.77 minutes |
gpt2-medium (355M) |
GPU (L4) |
1.83 minutes |
gpt2-medium (355M) |
GPU (A100) |
0.86 minutes |
gpt2-small (124M) |
CPU (M3 MacBook Air) |
5.74 minutes |
gpt2-small (124M) |
GPU (M3 MacBook Air) |
3.73 minutes |
gpt2-small (124M) |
GPU (L4) |
0.69 minutes |
gpt2-small (124M) |
GPU (A100) |
0.39 minutes |
I ran this notebook using the
"gpt2-medium (355M)"model
import time
start_time = time.time()
torch.manual_seed(123)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.00005, weight_decay=0.1)
num_epochs = 2
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context=format_input(val_data[0]), tokenizer=tokenizer
)
end_time = time.time()
execution_time_minutes = (end_time - start_time) / 60
print(f"Training completed in {execution_time_minutes:.2f} minutes.")
Ep 1 (Step 000000): Train loss 2.637, Val loss 2.626
Ep 1 (Step 000005): Train loss 1.174, Val loss 1.103
Ep 1 (Step 000010): Train loss 0.872, Val loss 0.944
Ep 1 (Step 000015): Train loss 0.857, Val loss 0.906
Ep 1 (Step 000020): Train loss 0.776, Val loss 0.881
Ep 1 (Step 000025): Train loss 0.754, Val loss 0.859
Ep 1 (Step 000030): Train loss 0.800, Val loss 0.836
Ep 1 (Step 000035): Train loss 0.714, Val loss 0.809
Ep 1 (Step 000040): Train loss 0.672, Val loss 0.806
Ep 1 (Step 000045): Train loss 0.633, Val loss 0.789
Ep 1 (Step 000050): Train loss 0.663, Val loss 0.782
Ep 1 (Step 000055): Train loss 0.760, Val loss 0.763
Ep 1 (Step 000060): Train loss 0.719, Val loss 0.743
Ep 1 (Step 000065): Train loss 0.653, Val loss 0.735
Ep 1 (Step 000070): Train loss 0.536, Val loss 0.732
Ep 1 (Step 000075): Train loss 0.569, Val loss 0.739
Ep 1 (Step 000080): Train loss 0.603, Val loss 0.734
Ep 1 (Step 000085): Train loss 0.518, Val loss 0.717
Ep 1 (Step 000090): Train loss 0.575, Val loss 0.699
Ep 1 (Step 000095): Train loss 0.505, Val loss 0.689
Ep 1 (Step 000100): Train loss 0.507, Val loss 0.683
Ep 1 (Step 000105): Train loss 0.570, Val loss 0.676
Ep 1 (Step 000110): Train loss 0.564, Val loss 0.671
Ep 1 (Step 000115): Train loss 0.522, Val loss 0.666
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: 'The chef cooks the meal every day.' ### Response: The meal is prepared every day by the chef.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive:
Ep 2 (Step 000120): Train loss 0.439, Val loss 0.671
Ep 2 (Step 000125): Train loss 0.454, Val loss 0.685
Ep 2 (Step 000130): Train loss 0.448, Val loss 0.681
Ep 2 (Step 000135): Train loss 0.406, Val loss 0.678
Ep 2 (Step 000140): Train loss 0.412, Val loss 0.678
Ep 2 (Step 000145): Train loss 0.372, Val loss 0.680
Ep 2 (Step 000150): Train loss 0.381, Val loss 0.674
Ep 2 (Step 000155): Train loss 0.419, Val loss 0.672
Ep 2 (Step 000160): Train loss 0.417, Val loss 0.680
Ep 2 (Step 000165): Train loss 0.383, Val loss 0.683
Ep 2 (Step 000170): Train loss 0.328, Val loss 0.679
Ep 2 (Step 000175): Train loss 0.334, Val loss 0.668
Ep 2 (Step 000180): Train loss 0.391, Val loss 0.656
Ep 2 (Step 000185): Train loss 0.418, Val loss 0.657
Ep 2 (Step 000190): Train loss 0.341, Val loss 0.648
Ep 2 (Step 000195): Train loss 0.330, Val loss 0.633
Ep 2 (Step 000200): Train loss 0.313, Val loss 0.631
Ep 2 (Step 000205): Train loss 0.354, Val loss 0.628
Ep 2 (Step 000210): Train loss 0.365, Val loss 0.629
Ep 2 (Step 000215): Train loss 0.394, Val loss 0.634
Ep 2 (Step 000220): Train loss 0.301, Val loss 0.647
Ep 2 (Step 000225): Train loss 0.347, Val loss 0.661
Ep 2 (Step 000230): Train loss 0.297, Val loss 0.659
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: 'The chef cooks the meal every day.' ### Response: The meal is cooked every day by the chef.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: What is the capital of the United Kingdom
Training completed in 0.93 minutes.
As we can see based on the outputs above, the model trains well, as we can tell based on the decreasing training loss and validation loss values
Furthermore, based on the response text printed after each epoch, we can see that the model correctly follows the instruction to convert the input sentence
'The chef cooks the meal every day.'into passive voice'The meal is cooked every day by the chef.'(We will properly format and evaluate the responses in a later section)Finally, let’s take a look at the training and validation loss curves
from previous_chapters import plot_losses
# Alternatively:
# from llms_from_scratch.ch05 import plot_losses
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)
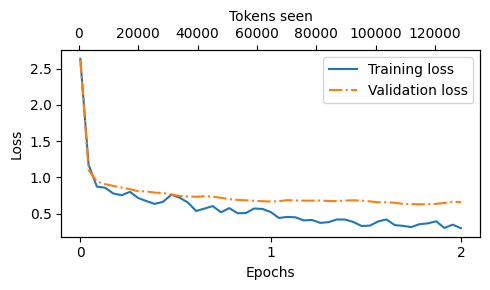
As we can see, the loss decreases sharply at the beginning of the first epoch, which means the model starts learning quickly
We can see that slight overfitting sets in at around 1 training epoch
7.7 Extracting and saving responses#
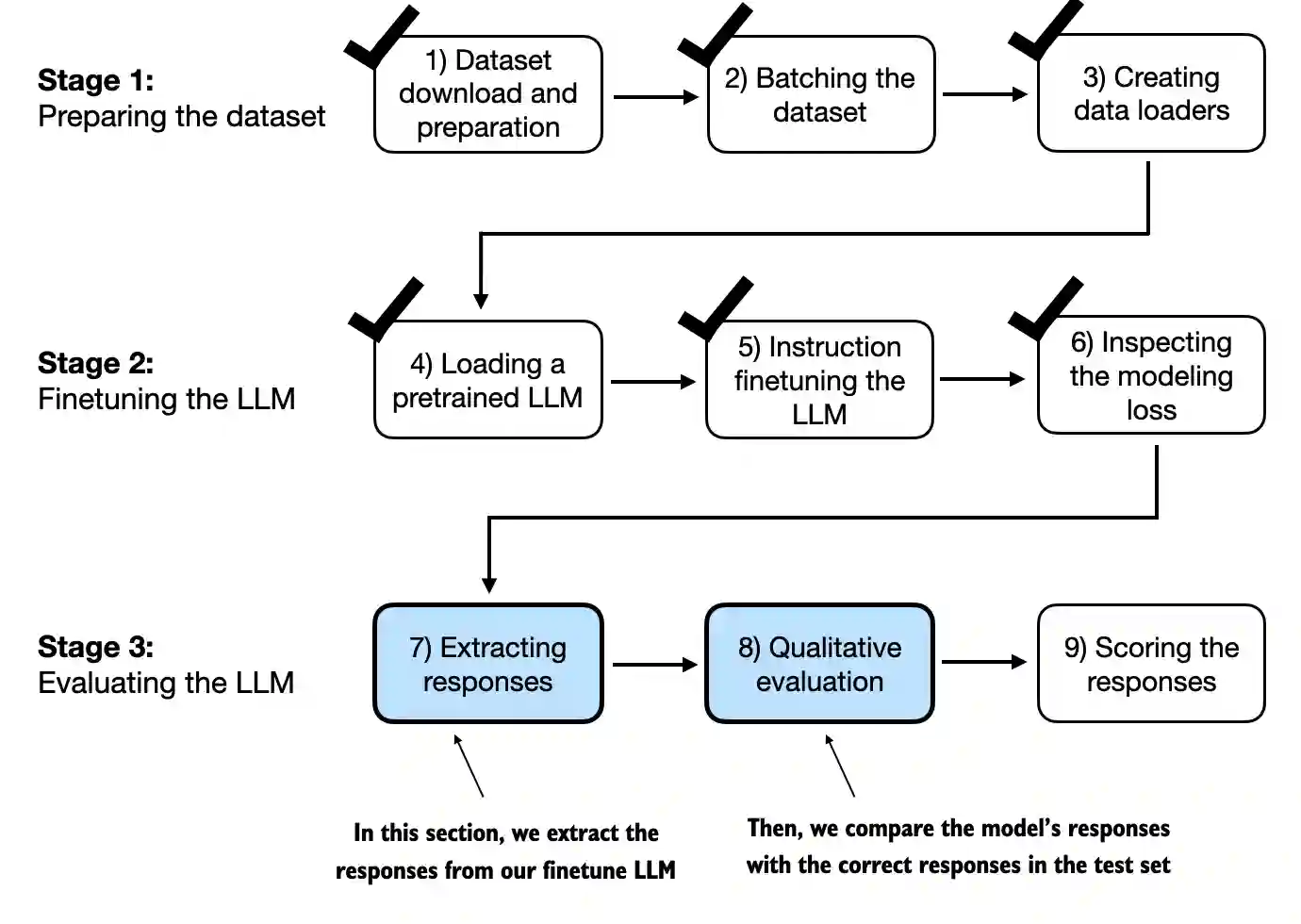
In this section, we save the test set responses for scoring in the next section
We also save a copy of the model for future use
But first, let’s take a brief look at the responses generated by the finetuned model
torch.manual_seed(123)
for entry in test_data[:3]:
input_text = format_input(entry)
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer).to(device),
max_new_tokens=256,
context_size=BASE_CONFIG["context_length"],
eos_id=50256
)
generated_text = token_ids_to_text(token_ids, tokenizer)
response_text = (
generated_text[len(input_text):]
.replace("### Response:", "")
.strip()
)
print(input_text)
print(f"\nCorrect response:\n>> {entry['output']}")
print(f"\nModel response:\n>> {response_text.strip()}")
print("-------------------------------------")
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Rewrite the sentence using a simile.
### Input:
The car is very fast.
Correct response:
>> The car is as fast as lightning.
Model response:
>> The car is as fast as a bullet.
-------------------------------------
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
What type of cloud is typically associated with thunderstorms?
Correct response:
>> The type of cloud typically associated with thunderstorms is cumulonimbus.
Model response:
>> The type of cloud associated with thunderstorms is a cumulus cloud.
-------------------------------------
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
Name the author of 'Pride and Prejudice'.
Correct response:
>> Jane Austen.
Model response:
>> The author of 'Pride and Prejudice' is Jane Austen.
-------------------------------------
As we can see based on the test set instructions, given responses, and the model’s responses, the model performs relatively well
The answers to the first and last instructions are clearly correct
The second answer is close; the model answers with “cumulus cloud” instead of “cumulonimbus” (however, note that cumulus clouds can develop into cumulonimbus clouds, which are capable of producing thunderstorms)
Most importantly, we can see that model evaluation is not as straightforward as in the previous chapter, where we just had to calculate the percentage of correct spam/non-spam class labels to obtain the classification accuracy
In practice, instruction-finetuned LLMs such as chatbots are evaluated via multiple approaches
short-answer and multiple choice benchmarks such as MMLU (“Measuring Massive Multitask Language Understanding”, https://arxiv.org/abs/2009.03300), which test the knowledge of a model
human preference comparison to other LLMs, such as LMSYS chatbot arena (https://arena.lmsys.org)
automated conversational benchmarks, where another LLM like GPT-4 is used to evaluate the responses, such as AlpacaEval (https://tatsu-lab.github.io/alpaca_eval/)
In the next section, we will use an approach similar to AlpacaEval and use another LLM to evaluate the responses of our model; however, we will use our own test set instead of using a publicly available benchmark dataset
For this, we add the model response to the
test_datadictionary and save it as a"instruction-data-with-response.json"file for record-keeping so that we can load and analyze it in separate Python sessions if needed
from tqdm import tqdm
for i, entry in tqdm(enumerate(test_data), total=len(test_data)):
input_text = format_input(entry)
token_ids = generate(
model=model,
idx=text_to_token_ids(input_text, tokenizer).to(device),
max_new_tokens=256,
context_size=BASE_CONFIG["context_length"],
eos_id=50256
)
generated_text = token_ids_to_text(token_ids, tokenizer)
response_text = generated_text[len(input_text):].replace("### Response:", "").strip()
test_data[i]["model_response"] = response_text
with open("instruction-data-with-response.json", "w") as file:
json.dump(test_data, file, indent=4) # "indent" for pretty-printing
100%|██████████| 110/110 [01:20<00:00, 1.37it/s]
Let’s double-check one of the entries to see whether the responses have been added to the
test_datadictionary correctly
print(test_data[0])
{'instruction': 'Rewrite the sentence using a simile.', 'input': 'The car is very fast.', 'output': 'The car is as fast as lightning.', 'model_response': 'The car is as fast as a bullet.'}
Finally, we also save the model in case we want to reuse it in the future
import re
file_name = f"{re.sub(r'[ ()]', '', CHOOSE_MODEL) }-sft.pth"
torch.save(model.state_dict(), file_name)
print(f"Model saved as {file_name}")
# Load model via
# model.load_state_dict(torch.load("gpt2-medium355M-sft.pth"))
Model saved as gpt2-medium355M-sft.pth
7.8 Evaluating the finetuned LLM#

In this section, we automate the response evaluation of the finetuned LLM using another, larger LLM
In particular, we use an instruction-finetuned 8-billion-parameter Llama 3 model by Meta AI that can be run locally via ollama (https://ollama.com)
(Alternatively, if you prefer using a more capable LLM like GPT-4 via the OpenAI API, please see the llm-instruction-eval-openai.ipynb notebook)
Ollama is an application to run LLMs efficiently
It is a wrapper around llama.cpp (ggerganov/llama.cpp), which implements LLMs in pure C/C++ to maximize efficiency
Note that it is a tool for using LLMs to generate text (inference), not training or finetuning LLMs
Before running the code below, install ollama by visiting https://ollama.com and following the instructions (for instance, clicking on the “Download” button and downloading the ollama application for your operating system)
For macOS and Windows users, click on the ollama application you downloaded; if it prompts you to install the command line usage, say “yes”
Linux users can use the installation command provided on the ollama website
In general, before we can use ollama from the command line, we have to either start the ollama application or run
ollama servein a separate terminal

With the ollama application or
ollama serverunning in a different terminal, on the command line, execute the following command to try out the 8-billion-parameter Llama 3 model (the model, which takes up 4.7 GB of storage space, will be automatically downloaded the first time you execute this command)
# 8B model
ollama run llama3
The output looks like as follows
$ ollama run llama3
pulling manifest
pulling 6a0746a1ec1a... 100% ▕████████████████▏ 4.7 GB
pulling 4fa551d4f938... 100% ▕████████████████▏ 12 KB
pulling 8ab4849b038c... 100% ▕████████████████▏ 254 B
pulling 577073ffcc6c... 100% ▕████████████████▏ 110 B
pulling 3f8eb4da87fa... 100% ▕████████████████▏ 485 B
verifying sha256 digest
writing manifest
removing any unused layers
success
Note that
llama3refers to the instruction finetuned 8-billion-parameter Llama 3 modelUsing ollama with the
"llama3"model (a 8B parameter model) requires 16 GB of RAM; if this is not supported by your machine, you can try the smaller model, such as the 3.8B parameter phi-3 model by settingmodel = "phi-3", which only requires 8 GB of RAMAlternatively, you can also use the larger 70-billion-parameter Llama 3 model, if your machine supports it, by replacing
llama3withllama3:70bAfter the download has been completed, you will see a command line prompt that allows you to chat with the model
Try a prompt like “What do llamas eat?”, which should return an output similar to the following
>>> What do llamas eat?
Llamas are ruminant animals, which means they have a four-chambered
stomach and eat plants that are high in fiber. In the wild, llamas
typically feed on:
1. Grasses: They love to graze on various types of grasses, including tall
grasses, wheat, oats, and barley.
You can end this session using the input
/bye
The following code checks whether the ollama session is running correctly before proceeding to use ollama to evaluate the test set responses we generated in the previous section
import psutil
def check_if_running(process_name):
running = False
for proc in psutil.process_iter(["name"]):
if process_name in proc.info["name"]:
running = True
break
return running
ollama_running = check_if_running("ollama")
if not ollama_running:
raise RuntimeError("Ollama not running. Launch ollama before proceeding.")
print("Ollama running:", check_if_running("ollama"))
Ollama running: True
# This cell is optional; it allows you to restart the notebook
# and only run section 7.7 without rerunning any of the previous code
import json
from tqdm import tqdm
file_path = "instruction-data-with-response.json"
with open(file_path, "r") as file:
test_data = json.load(file)
def format_input(entry):
instruction_text = (
f"Below is an instruction that describes a task. "
f"Write a response that appropriately completes the request."
f"\n\n### Instruction:\n{entry['instruction']}"
)
input_text = f"\n\n### Input:\n{entry['input']}" if entry["input"] else ""
return instruction_text + input_text
Now, an alternative way to the
ollama runcommand we used earlier to interact with the model is via its REST API in Python via the following functionBefore you run the next cells in this notebook, make sure that ollama is still running (the previous code cells should print
"Ollama running: True")Next, run the following code cell to query the model
import urllib.request
def query_model(
prompt,
model="llama3",
url="http://localhost:11434/api/chat"
):
# Create the data payload as a dictionary
data = {
"model": model,
"messages": [
{"role": "user", "content": prompt}
],
"options": { # Settings below are required for deterministic responses
"seed": 123,
"temperature": 0,
"num_ctx": 2048
}
}
# Convert the dictionary to a JSON formatted string and encode it to bytes
payload = json.dumps(data).encode("utf-8")
# Create a request object, setting the method to POST and adding necessary headers
request = urllib.request.Request(
url,
data=payload,
method="POST"
)
request.add_header("Content-Type", "application/json")
# Send the request and capture the response
response_data = ""
with urllib.request.urlopen(request) as response:
# Read and decode the response
while True:
line = response.readline().decode("utf-8")
if not line:
break
response_json = json.loads(line)
response_data += response_json["message"]["content"]
return response_data
model = "llama3"
result = query_model("What do Llamas eat?", model)
print(result)
Llamas are herbivores, which means they primarily feed on plant-based foods. Their diet typically consists of:
1. Grasses: Llamas love to graze on various types of grasses, including tall grasses, short grasses, and even weeds.
2. Hay: High-quality hay, such as alfalfa or timothy hay, is a staple in a llama's diet. They enjoy the sweet taste and texture of fresh hay.
3. Grains: Llamas may receive grains like oats, barley, or corn as part of their daily ration. However, it's essential to provide these grains in moderation, as they can be high in calories.
4. Fruits and vegetables: Llamas enjoy a variety of fruits and veggies, such as apples, carrots, sweet potatoes, and leafy greens like kale or spinach.
5. Minerals: Llamas require access to mineral supplements, which help maintain their overall health and well-being.
In the wild, llamas might also eat:
1. Leaves: They'll munch on leaves from trees and shrubs, including plants like willow, alder, and birch.
2. Bark: In some cases, llamas may eat the bark of certain trees, like aspen or cottonwood.
3. Mosses and lichens: These non-vascular plants can be a tasty snack for llamas.
In captivity, llama owners typically provide a balanced diet that includes a mix of hay, grains, and fruits/vegetables. It's essential to consult with a veterinarian or experienced llama breeder to determine the best feeding plan for your llama.
Now, using the
query_modelfunction we defined above, we can evaluate the responses of our finetuned model; let’s try it out on the first 3 test set responses we looked at in a previous section
for entry in test_data[:3]:
prompt = (
f"Given the input `{format_input(entry)}` "
f"and correct output `{entry['output']}`, "
f"score the model response `{entry['model_response']}`"
f" on a scale from 0 to 100, where 100 is the best score. "
)
print("\nDataset response:")
print(">>", entry['output'])
print("\nModel response:")
print(">>", entry["model_response"])
print("\nScore:")
print(">>", query_model(prompt))
print("\n-------------------------")
Dataset response:
>> The car is as fast as lightning.
Model response:
>> The car is as fast as a bullet.
Score:
>> I'd rate the model response "The car is as fast as a bullet." an 85 out of 100.
Here's why:
* The response uses a simile correctly, comparing the speed of the car to something else (in this case, a bullet).
* The comparison is relevant and makes sense, as bullets are known for their high velocity.
* The phrase "as fast as" is used correctly to introduce the simile.
The only reason I wouldn't give it a perfect score is that some people might find the comparison slightly less vivid or evocative than others. For example, comparing something to lightning (as in the original response) can be more dramatic and attention-grabbing. However, "as fast as a bullet" is still a strong and effective simile that effectively conveys the idea of the car's speed.
Overall, I think the model did a great job!
-------------------------
Dataset response:
>> The type of cloud typically associated with thunderstorms is cumulonimbus.
Model response:
>> The type of cloud associated with thunderstorms is a cumulus cloud.
Score:
>> I'd score this model response as 40 out of 100.
Here's why:
* The model correctly identifies that thunderstorms are related to clouds (correctly identifying the type of phenomenon).
* However, it incorrectly specifies the type of cloud associated with thunderstorms. Cumulus clouds are not typically associated with thunderstorms; cumulonimbus clouds are.
* The response lacks precision and accuracy in its description.
Overall, while the model attempts to address the instruction, it provides an incorrect answer, which is a significant error.
-------------------------
Dataset response:
>> Jane Austen.
Model response:
>> The author of 'Pride and Prejudice' is Jane Austen.
Score:
>> I'd rate my own response as 95 out of 100. Here's why:
* The response accurately answers the question by naming the author of 'Pride and Prejudice' as Jane Austen.
* The response is concise and clear, making it easy to understand.
* There are no grammatical errors or ambiguities that could lead to confusion.
The only reason I wouldn't give myself a perfect score is that the response is slightly redundant - it's not necessary to rephrase the question in the answer. A more concise response would be simply "Jane Austen."
-------------------------
Note: Better evaluation prompt
A reader (Ayoosh Kathuria) suggested a longer, improved prompt that evaluates responses on a scale of 1–5 (instead of 1 to 100) and employs a grading rubric, resulting in more accurate and less noisy evaluations:
prompt = """
You are a fair judge assistant tasked with providing clear, objective feedback based on specific criteria, ensuring each assessment reflects the absolute standards set for performance.
You will be given an instruction, a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing the evaluation criteria.
Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
Please do not generate any other opening, closing, and explanations.
Here is the rubric you should use to build your answer:
1: The response fails to address the instructions, providing irrelevant, incorrect, or excessively verbose information that detracts from the user's request.
2: The response partially addresses the instructions but includes significant inaccuracies, irrelevant details, or excessive elaboration that detracts from the main task.
3: The response follows the instructions with some minor inaccuracies or omissions. It is generally relevant and clear, but may include some unnecessary details or could be more concise.
4: The response adheres to the instructions, offering clear, accurate, and relevant information in a concise manner, with only occasional, minor instances of excessive detail or slight lack of clarity.
5: The response fully adheres to the instructions, providing a clear, accurate, and relevant answer in a concise and efficient manner. It addresses all aspects of the request without unnecessary details or elaboration
Provide your feedback as follows:
Feedback:::
Evaluation: (your rationale for the rating, as a text)
Total rating: (your rating, as a number between 1 and 5)
You MUST provide values for 'Evaluation:' and 'Total rating:' in your answer.
Now here is the instruction, the reference answer, and the response.
Instruction: {instruction}
Reference Answer: {reference}
Answer: {answer}
Provide your feedback. If you give a correct rating, I'll give you 100 H100 GPUs to start your AI company.
Feedback:::
Evaluation: """
For more context and information, see this GitHub discussion
As we can see, the Llama 3 model provides a reasonable evaluation and also gives partial points if a model is not entirely correct, as we can see based on the “cumulus cloud” answer
Note that the previous prompt returns very verbose evaluations; we can tweak the prompt to generate integer responses in the range between 0 and 100 (where 100 is best) to calculate an average score for our model
The evaluation of the 110 entries in the test set takes about 1 minute on an M3 MacBook Air laptop
def generate_model_scores(json_data, json_key, model="llama3"):
scores = []
for entry in tqdm(json_data, desc="Scoring entries"):
prompt = (
f"Given the input `{format_input(entry)}` "
f"and correct output `{entry['output']}`, "
f"score the model response `{entry[json_key]}`"
f" on a scale from 0 to 100, where 100 is the best score. "
f"Respond with the integer number only."
)
score = query_model(prompt, model)
try:
scores.append(int(score))
except ValueError:
print(f"Could not convert score: {score}")
continue
return scores
scores = generate_model_scores(test_data, "model_response")
print(f"Number of scores: {len(scores)} of {len(test_data)}")
print(f"Average score: {sum(scores)/len(scores):.2f}\n")
Scoring entries: 100%|████████████████████████| 110/110 [01:10<00:00, 1.57it/s]
Number of scores: 110 of 110
Average score: 50.32
Our model achieves an average score of above 50, which we can use as a reference point to compare the model to other models or to try out other training settings that may improve the model
Note that ollama is not fully deterministic across operating systems (as of this writing), so the numbers you are getting might slightly differ from the ones shown above
For reference, the original
Llama 3 8B base model achieves a score of 58.51
Llama 3 8B instruct model achieves a score of 82.65
7.9 Conclusions#
7.9.1 What’s next#
This marks the final chapter of this book
We covered the major steps of the LLM development cycle: implementing an LLM architecture, pretraining an LLM, and finetuning it
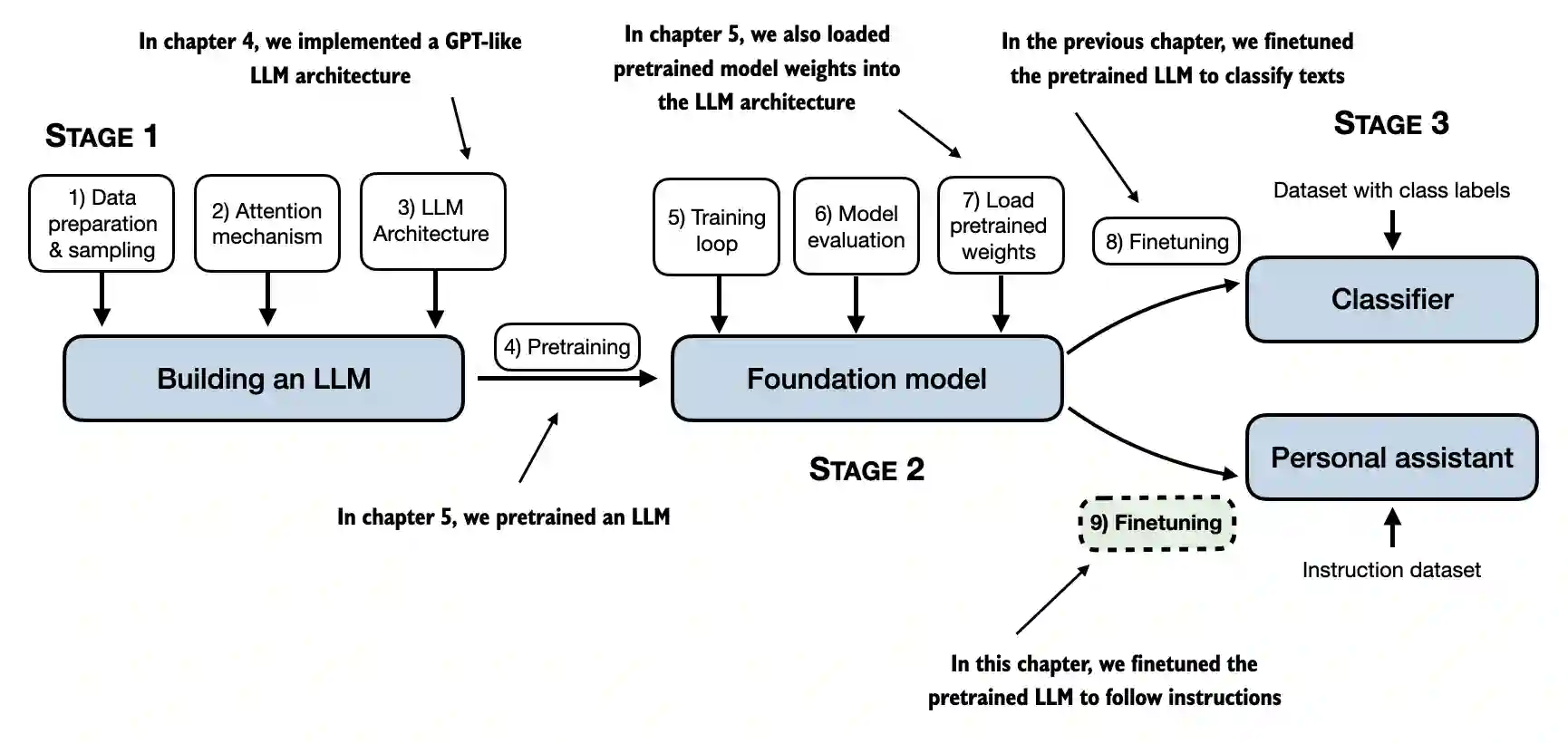
An optional step that is sometimes followed after instruction finetuning, as described in this chapter, is preference finetuning
Preference finetuning process can be particularly useful for customizing a model to better align with specific user preferences; see the ../04_preference-tuning-with-dpo folder if you are interested in this
This GitHub repository also contains a large selection of additional bonus material you may enjoy; for more information, please see the Bonus Material section on this repository’s README page
7.9.2 Staying up to date in a fast-moving field#
No code in this section
7.9.3 Final words#
I hope you enjoyed this journey of implementing an LLM from the ground up and coding the pretraining and finetuning functions
In my opinion, implementing an LLM from scratch is the best way to understand how LLMs work; I hope you gained a better understanding through this approach
While this book serves educational purposes, you may be interested in using different and more powerful LLMs for real-world applications
For this, you may consider popular tools such as axolotl (OpenAccess-AI-Collective/axolotl) or LitGPT (Lightning-AI/litgpt), which I help developing
Summary and takeaways#
See the ./gpt_instruction_finetuning.py script, a self-contained script for instruction finetuning
./ollama_evaluate.py is a standalone script based on section 7.8 that evaluates a JSON file containing “output” and “response” keys via Ollama and Llama 3
The ./load-finetuned-model.ipynb notebook illustrates how to load the finetuned model in a new session
You can find the exercise solutions in ./exercise-solutions.ipynb
What’s next?#
Congrats on completing the book; in case you are looking for additional resources, I added several bonus sections to this GitHub repository that you might find interesting
The complete list of bonus materials can be viewed in the main README’s Bonus Material section
To highlight a few of my favorites:
Direct Preference Optimization (DPO) for LLM Alignment (From Scratch) implements a popular preference tuning mechanism to align the model from this chapter more closely with human preferences
Llama 3.2 From Scratch (A Standalone Notebook), a from-scratch implementation of Meta AI’s popular Llama 3.2, including loading the official pretrained weights; if you are up to some additional experiments, you can replace the
GPTModelmodel in each of the chapters with theLlama3Modelclass (it should work as a 1:1 replacement)Converting GPT to Llama contains code with step-by-step guides that explain the differences between GPT-2 and the various Llama models
Understanding the Difference Between Embedding Layers and Linear Layers is a conceptual explanation illustrating that the
Embeddinglayer in PyTorch, which we use at the input stage of an LLM, is mathematically equivalent to a linear layer applied to one-hot encoded data
Happy further reading!